Understanding Image Captioning with CNN, LSTM, and Attention
I wanted to understand more about CNN, LSTM, and attention mechanisms, so I decided to build an image captioning model. This post details my journey building a model that takes an image and generates a descriptive caption.

Caption: A person peacefully lies in a sunlit, flower-filled meadow surrounded by a serene forest, reminiscent of Studio Ghibli's enchanting landscapes.
Note
- This caption was generated by GPT (I know I should use latest models but wanted to build with this architecture first).
- In the future, I plan to experiment with more advanced models.
Introduction
The image captioning model performs one simple task: you input an image, and it generates a caption describing that image. It's conceptually similar to language translation, but instead of translating between languages, we're translating from visual data to text.
For this implementation, I used a CNN+LSTM+Attention architecture and the Flickr8k dataset.
Dataset
I used Flickr8k dataset it contains around 8,000 images with corresponding captions, though I only used 5,000 for my implementation.
Data Loader
Here's what the preprocessing looks like:
class ImageCaptionDataset(Dataset):
def __init__(self, root_dir, captions_file, tokenizer, transform=None):
self.root_dir = root_dir
self.captions_file = pd.read_csv(captions_file)
self.tokenizer = tokenizer
self.transform = transform
def __len__(self):
return len(self.captions_file)
def __getitem__(self, idx):
img_name = self.captions_file.iloc[idx, 0]
caption = self.captions_file.iloc[idx, 1]
img_path = f"{self.root_dir}/{img_name}"
image = Image.open(img_path).convert("RGB")
if self.transform is not None:
image = self.transform(image)
# Tokenize the caption
caption_tokens = self.tokenizer(caption, padding='max_length', max_length=30, truncation=True, return_tensors="pt")
caption_tensor = caption_tokens['input_ids'].squeeze() # Remove extra dimension
return image, caption_tensor
I updated the implementation to use BERT tokenizer instead of spacy (which was used in the reference implementation). This required changes to model.py, train.py, and inference.py. For images, I kept the transforms simple (no flip or normalize).
Architecture Overview
The architecture consists of three main components: Encoder (ResNet50) extracts features from images, Attention Block focuses on important parts of images with respect to captions, and Decoder (LSTM) generates captions based on image features.
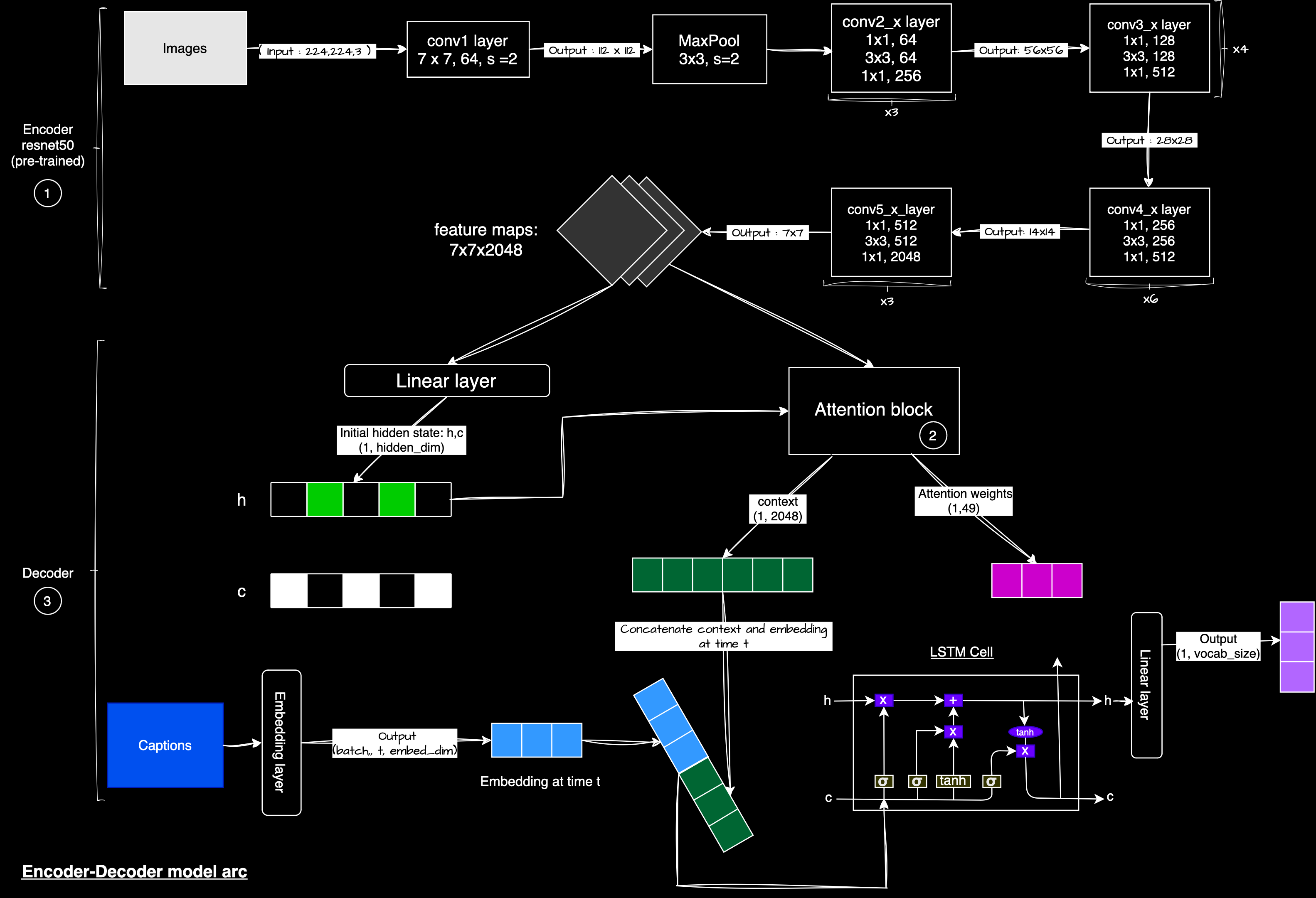
Image Captioning Architecture
Input Flow
Here's a simplified view of how data flows through the model: First, the image goes through the EncoderCNN to generate image features. These features are used to initialize the decoder states. Then for each word position, the previous word (or start token) is embedded, the current hidden state and image features are passed through attention to create a context vector, this word embedding and context vector are fed to the LSTM cell to update the hidden state, and finally the updated hidden state is passed through a fully connected layer to predict the next word. This process repeats until the end token is predicted or maximum length is reached.
EncoderCNN
The encoder uses a pre-trained ResNet-50 to extract features from images. These features are passed to the decoder for caption generation.
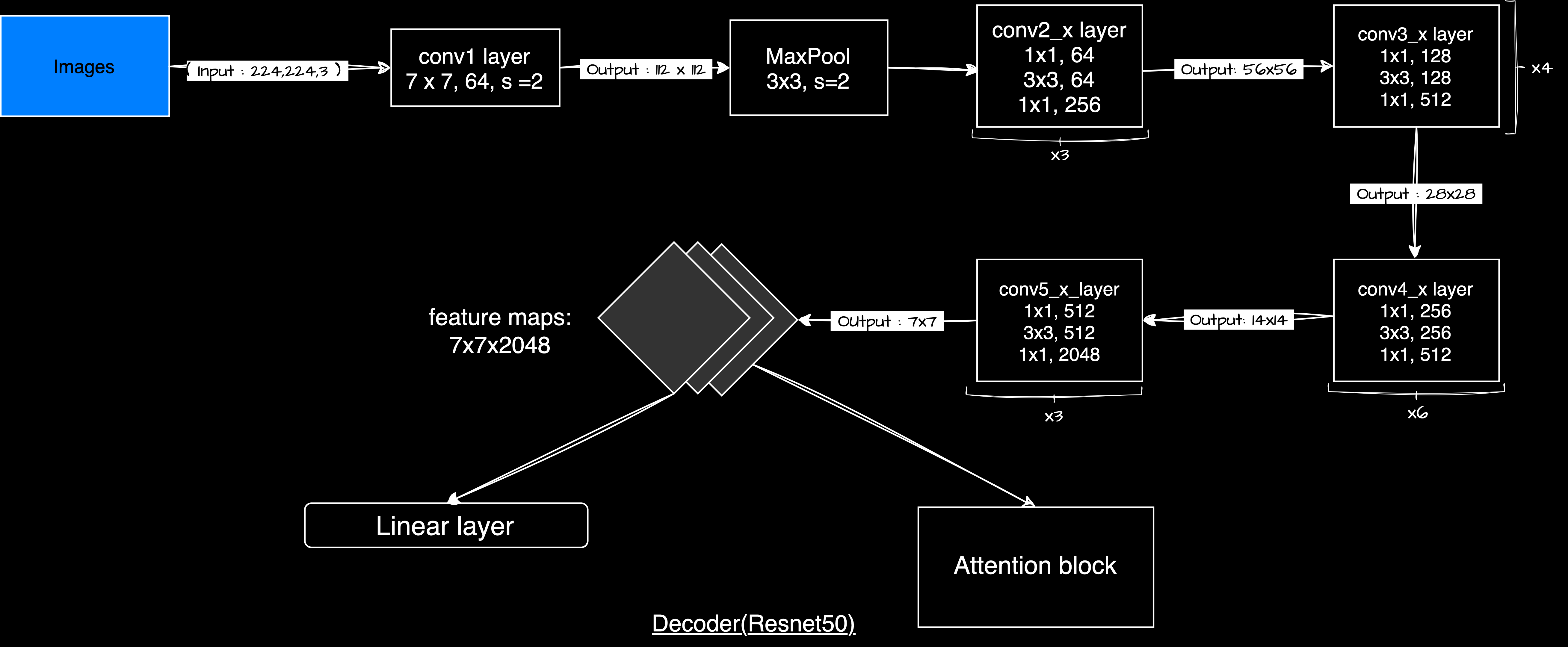
Encoder Architecture
class EncoderCNN(nn.Module):
def __init__(self):
super().__init__()
resnet = models.resnet50(pretrained=True)
# freeze resnet parameters to prevent updating during training
for param in resnet.parameters():
param.requires_grad_(False)
modules = list(resnet.children())[:-2]
self.resnet = nn.Sequential(*modules)
def forward(self, images):
features = self.resnet(images)
# reshape features for attention
features = features.permute(0, 2, 3, 1)
features = features.view(features.size(0), -1, features.size(-1))
return features
The EncoderCNN uses a ResNet-50 model pre-trained on ImageNet. Using pre-trained models helps with faster convergence and improved performance, especially with limited data.
We freeze its parameters so they don't change during training since we only perform a forward pass through this network:
for param in resnet.parameters():
param.requires_grad_(False)
We then remove the classification layers of ResNet-50 since we only need the feature maps:
modules = list(resnet.children())[:-2]
Forward Pass
The input images have shape (batch_size, 3, 224, 224), where 224×224 is the image size and 3 represents RGB channels. After passing through ResNet-50, the feature map shape becomes (batch_size, 2048, 7, 7), where 2048 is the number of features and 7×7 is the reduced spatial size. We rearrange the dimensions to prepare for attention processing. After permuting, the shape becomes (batch_size, 7, 7, 2048), and after flattening the spatial dimensions, it becomes (batch_size, 49, 2048).
features = features.permute(0, 2, 3, 1)
features = features.view(features.size(0), -1, features.size(-1))
Attention
Attention allows the model to selectively focus on the most relevant parts of the input image when generating each word in the caption. It calculates attention scores that guide the model in determining which parts of the image to emphasize at each step.
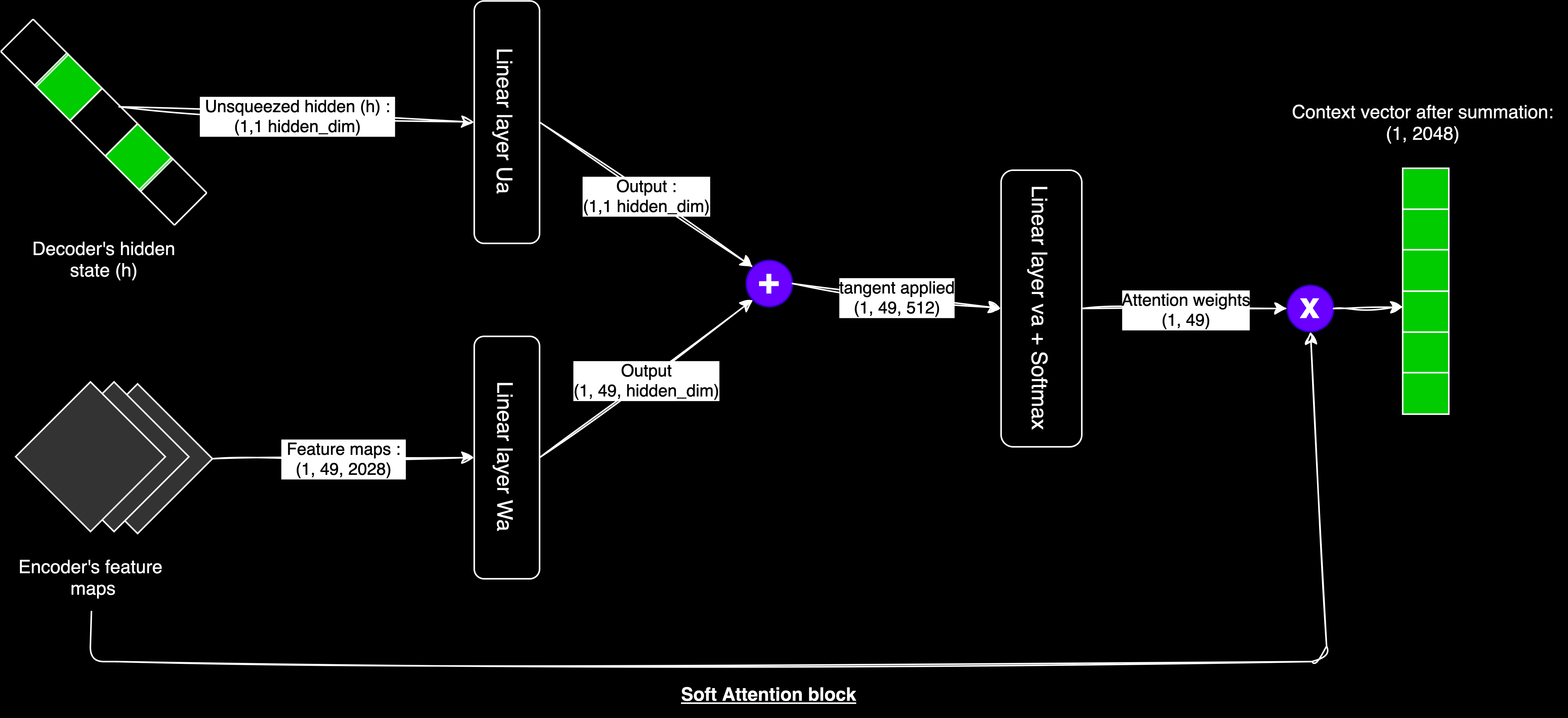
Attention Mechanism
class Attention(nn.Module):
def __init__(self, encoder_dim, decoder_dim, attention_dim):
super().__init__()
self.attention_dim = attention_dim
# linear layers for attention
self.W = nn.Linear(decoder_dim, attention_dim)
self.U = nn.Linear(encoder_dim, attention_dim)
self.A = nn.Linear(attention_dim, 1)
def forward(self, features, hidden_state):
u_hs = self.U(features)
w_ah = self.W(hidden_state)
combined_states = torch.tanh(u_hs + w_ah.unsqueeze(1))
attention_scores = self.A(combined_states)
attention_scores = attention_scores.squeeze(2)
alpha = F.softmax(attention_scores, dim=1) # attention_weight
# apply attention weights to features
attention_weights = features * alpha.unsqueeze(2)
attention_weights = attention_weights.sum(dim=1)
return alpha, attention_weights
The Attention class uses three linear layers to calculate attention scores: self.W maps the decoder's hidden state (decoder_dim) to the attention space (attention_dim), self.U maps the encoder's features (encoder_dim) to the attention space (attention_dim), and self.A reduces the combined attention space to a single value (attention score).
Forward Pass
The attention mechanism takes two inputs: image features from the encoder (shape: batch_size, 49, encoder_dim) and the current hidden state of the decoder (shape: batch_size, decoder_dim). First, both inputs are projected into the attention space. We add an extra dimension to w_ah for proper addition, combine the states with element-wise addition, and apply tanh activation. The combined states are passed through another linear layer to calculate attention scores, which are then normalized with softmax.
The attention calculation can be formalized as:
scoreij=vTatanh(Uaht−1+Wahj)
αij=exp(scoreij)∑kexp(scoreik)
ct=∑jαijhj
Finally, we apply the attention weights to the features and sum them to create the context vector.
DecoderRNN
The DecoderRNN generates captions based on the image features. It uses an LSTM (Long Short-Term Memory) network to process text sequentially, taking attention-weighted context vectors and previously generated words to produce the next word.
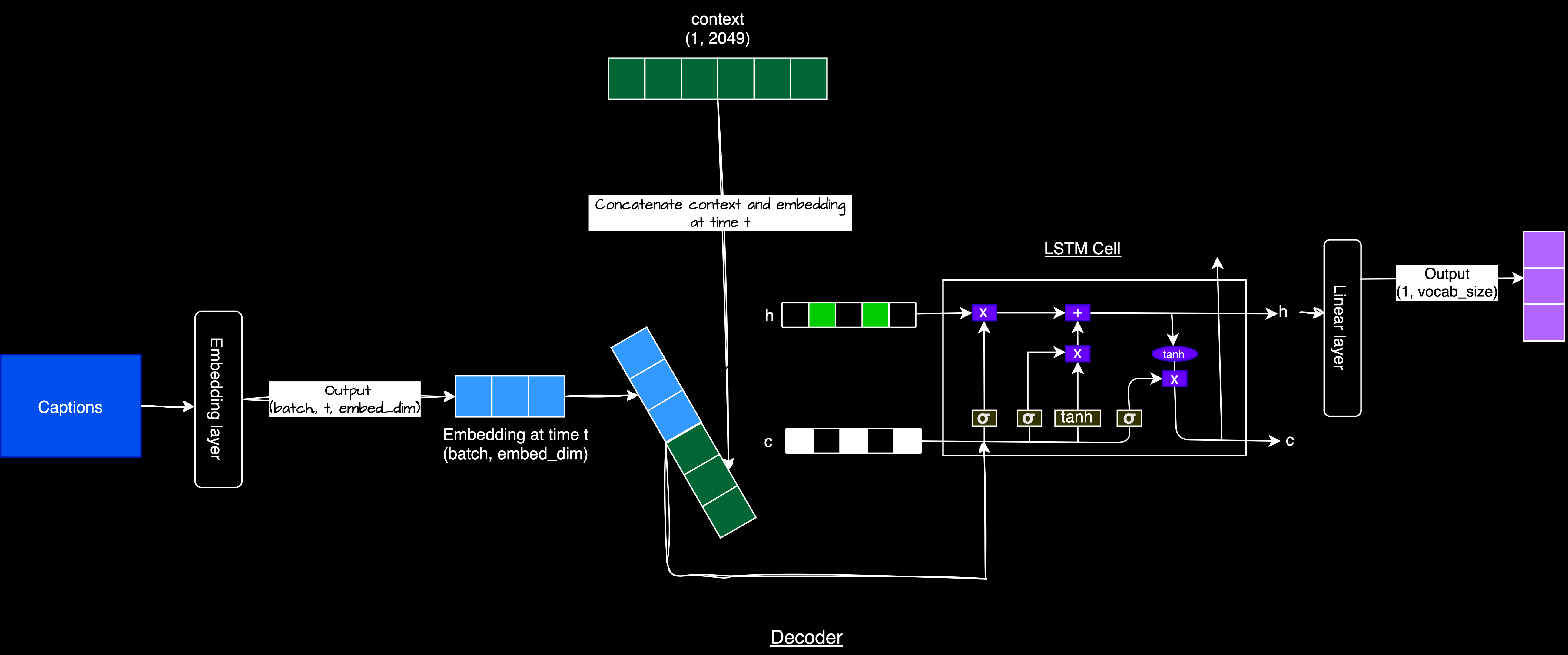
Decoder Architecture
class DecoderRNN(nn.Module):
def __init__(self, embed_size, attention_dim, encoder_dim, decoder_dim, drop_prob=0.3):
super().__init__()
self.attention = Attention(encoder_dim, decoder_dim, attention_dim)
# embedding layer using bert tokenizer vocabulary
self.embedding = nn.Embedding(len(BertTokenizer.from_pretrained('bert-base-uncased')), embed_size)
# initialize hidden and cell states
self.init_h = nn.Linear(encoder_dim, decoder_dim)
self.init_c = nn.Linear(encoder_dim, decoder_dim)
# lstm cell for sequence generation
self.lstm_cell = nn.LSTMCell(embed_size + encoder_dim, decoder_dim, bias=True)
# fc layer for output
self.fcn = nn.Linear(decoder_dim, self.embedding.num_embeddings)
self.drop = nn.Dropout(drop_prob)
def forward(self, features, captions):
embeds = self.embedding(captions)
h, c = self.init_hidden_state(features)
seq_length = captions.size(1) - 1
batch_size = captions.size(0)
num_features = features.size(1)
# initialize tensors to store predictions and attention weights
preds = torch.zeros(batch_size, seq_length, self.embedding.num_embeddings).to(features.device)
alphas = torch.zeros(batch_size, seq_length, num_features).to(features.device)
# generate sequence
for s in range(seq_length):
alpha, context = self.attention(features, h)
lstm_input = torch.cat((embeds[:, s], context), dim=1)
h, c = self.lstm_cell(lstm_input, (h, c))
output = self.fcn(self.drop(h))
preds[:, s] = output
alphas[:, s] = alpha
return preds, alphas
The process follows these steps: The image is encoded into feature maps by the EncoderCNN. These features initialize the decoder's hidden and cell states. The decoder generates the caption word by word: Attention computes a context vector based on the current hidden state and image features, the context vector is concatenated with the previous word embedding as input to the LSTM cell, the LSTM cell updates its hidden and cell states, the updated hidden state generates the probability distribution for the next word, and outputs and attention weights are stored for each time step. During training, each word of the caption is embedded and used as input for the next time step, a technique known as "teacher forcing."
The Complete Story
EncoderCNN Class uses pre-trained ResNet50 with frozen parameters, removes classification layers to extract feature maps, and reshapes output for the attention mechanism.
Attention Class implements Bahdanau attention, transforms encoder features and decoder states, calculates attention scores and weights, and produces context vector for the decoder.
DecoderRNN Class integrates the attention module, uses BERT tokenizer vocabulary for word embedding, processes each word sequentially with LSTM, and generates output probabilities and stores attention weights.
Training
I trained the model on two T4 GPUs from Kaggle with the following hyperparameters:
embed_size=300
attention_dim=256
encoder_dim=2048
decoder_dim=512
learning_rate = 3e-4
batch = 32
epochs = 100
For optimization, I used Adam optimizer and CrossEntropyLoss:
criterion = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_token_id)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5, verbose=True)
I used a dropout rate of 0.4/0.5 and encountered overfitting. Currently, I'm training with additional improvements like increased dropout, learning rate scheduling, and gradient clipping.
Training Loop
def train(model, train_loader, test_loader, criterion, optimizer, num_epochs, tokenizer):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# multiple GPUs support
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs")
model = DataParallel(model)
# Initialize the ReduceLROnPlateau scheduler
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5, verbose=True)
print_every = 150
# Create a directory to store checkpoints
os.makedirs('checkpoints', exist_ok=True)
for epoch in range(1, num_epochs + 1):
model.train()
running_loss = 0.0
correct_predictions = 0
total_predictions = 0
for idx, (image, captions) in enumerate(train_loader):
image, captions = image.to(device), captions.to(device)
optimizer.zero_grad()
outputs, _ = model(image, captions)
targets = captions[:, 1:] # shifted target for teacher forcing
loss = criterion(outputs.view(-1, tokenizer.vocab_size), targets.reshape(-1))
loss.backward()
optimizer.step()
running_loss += loss.item()
# calculating accuracy, ignoring padding index
_, predicted = outputs.max(2)
mask = targets != tokenizer.pad_token_id
correct_predictions += (predicted == targets).masked_select(mask).sum().item()
total_predictions += mask.sum().item()
if (idx + 1) % print_every == 0:
avg_loss = running_loss / print_every
accuracy = correct_predictions / total_predictions
print(f"Epoch: {epoch}/{num_epochs}, Batch: {idx+1}/{len(train_loader)}, Loss: {avg_loss:.5f}, Accuracy: {accuracy:.5f}")
running_loss = 0.0
correct_predictions = 0
total_predictions = 0
# evaluate the model on the test set
model.eval()
test_loss = 0.0
test_correct = 0
test_total = 0
with torch.inference_mode():
for image, captions in test_loader:
image, captions = image.to(device), captions.to(device)
outputs, _ = model(image, captions)
targets = captions[:, 1:]
loss = criterion(outputs.view(-1, tokenizer.vocab_size), targets.reshape(-1))
test_loss += loss.item()
_, predicted = outputs.max(2)
mask = targets != tokenizer.pad_token_id
test_correct += (predicted == targets).masked_select(mask).sum().item()
test_total += mask.sum().item()
avg_test_loss = test_loss / len(test_loader)
test_accuracy = test_correct / test_total
print(f"Epoch: {epoch}/{num_epochs}, Test Loss: {avg_test_loss:.5f}, Test Accuracy: {test_accuracy:.5f}")
# Step the scheduler
scheduler.step(avg_test_loss)
# Save model weights at every epoch
if isinstance(model, DataParallel):
torch.save(model.module.state_dict(), f"checkpoints/model_weights_epoch_{epoch}.pth")
else:
torch.save(model.state_dict(), f"checkpoints/model_weights_epoch_{epoch}.pth")
print(f"Model weights saved for epoch {epoch}")
Inference
For generation, I implemented a simple greedy search algorithm that selects the most probable word at each step. In the future, I plan to implement beam search, which maintains the top-k most probable sequences.
def predict_caption(image_path, model, tokenizer, max_len=50):
# load and preprocess the image
image = Image.open(image_path).convert("RGB")
image_tensor = transform(image).unsqueeze(0).to(device)
# encode the image
features = model.encoder(image_tensor)
# initialize the hidden and cell states
h, c = model.decoder.init_hidden_state(features)
# start the caption with the [CLS] token
word = torch.tensor([tokenizer.cls_token_id]).to(device)
embeds = model.decoder.embedding(word)
captions = []
alphas = []
for _ in range(max_len):
alpha, context = model.decoder.attention(features, h)
alphas.append(alpha.cpu().detach().numpy())
lstm_input = torch.cat((embeds.squeeze(1), context), dim=1)
h, c = model.decoder.lstm_cell(lstm_input, (h, c))
output = model.decoder.fcn(model.decoder.drop(h))
predicted_word_idx = output.argmax(dim=1)
captions.append(predicted_word_idx.item())
# break if [SEP] token is generated
if predicted_word_idx.item() == tokenizer.sep_token_id:
break
embeds = model.decoder.embedding(predicted_word_idx.unsqueeze(0))
# convert word indices to words, skipping special tokens
caption = tokenizer.decode(captions, skip_special_tokens=True)
return image, caption
I enjoyed building this model and learned a lot in the process. Good codebases, articles, and papers were essential for understanding the components. My next goal is to build image captioning with GPT2 and ViT, and then with CLIP.
References
1. Kelvin Xu, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel, Yoshua Bengio. (April 19 2016). Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.
2. Andrej Karpathy. (May 21 2105). The Unreasonable Effectiveness of Recurrent Neural Networks.
3. Lilian Weng. (June 24, 2018). Attention? Attention!
4. Sagar Vinodababu. A PyTorch Tutorial to Image Captioning.
5. Image Captioning with Attention by Artyom Makarov.
6. PyTorch DataLoader: Understand and implement custom collate function by Fabrizio Damicelli
7. Pytorch Image Captioning Tutorial(without attention) by Aladdin Persson